
Understanding eXIAA: When Explainability Itself Becomes a Target for Attack
Understanding eXIAA: When Explainability Itself Becomes a Target for Attack
Leonardo Pesce, Jiawen Wei, and Gianmarco Mengaldo from the National University of Singapore have introduced a striking vulnerability in one of machine learning’s most trusted safeguards: post-hoc explainability methods.[1][2][3] Their paper, “eXIAA: eXplainable Injections for Adversarial Attack,” presents a novel black-box adversarial attack that can dramatically alter explanations provided by explainability methods while maintaining both the model’s predictions and visual imperceptibility. The implications are profound and unsettling for those who have come to rely on explainability as a mechanism for understanding and auditing machine learning systems.
The Rise of Post-Hoc Explainability
To fully appreciate the significance of this research, we must first understand the landscape that made it necessary. Over the past decade, explainability—particularly post-hoc explainability—has become a cornerstone of responsible AI development.
The explainability imperative emerged from necessity. As deep learning models achieved unprecedented accuracy across domains like computer vision, natural language processing, and healthcare, they simultaneously became increasingly opaque. Unlike earlier symbolic AI systems and rule-based approaches, modern neural networks operate as black boxes, their internal decision-making processes inscrutable to human observers. Regulators, practitioners, and the public demanded answers: why did the model make this decision? What features influenced this prediction?
Post-hoc explainability methods answered this call by providing mechanisms to inspect trained models after the fact, without requiring changes to the model architecture itself.[1][2][5] Methods like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) became ubiquitous tools for organizations seeking to comply with emerging regulations, audit model behavior, and build trust with stakeholders. These methods work by computing feature attributions—numerical scores that indicate how much each input feature contributed to a particular prediction. In computer vision, this typically manifests as saliency maps or attention heatmaps showing which regions of an image influenced the model’s decision.
The appeal was undeniable: these methods were model-agnostic (working with any model), required no retraining, and could be retrofitted to existing systems. For practitioners seeking to maintain state-of-the-art performance while satisfying explainability requirements, post-hoc methods represented an elegant compromise.
The EXIAA Attack: A Critical Vulnerability
The elegance of this compromise, however, rests on a critical assumption: that explanations, while possibly limited in scope, are at least faithful representations of what the model actually relies upon. Pesce, Wei, and Mengaldo’s work systematically dismantles this assumption.
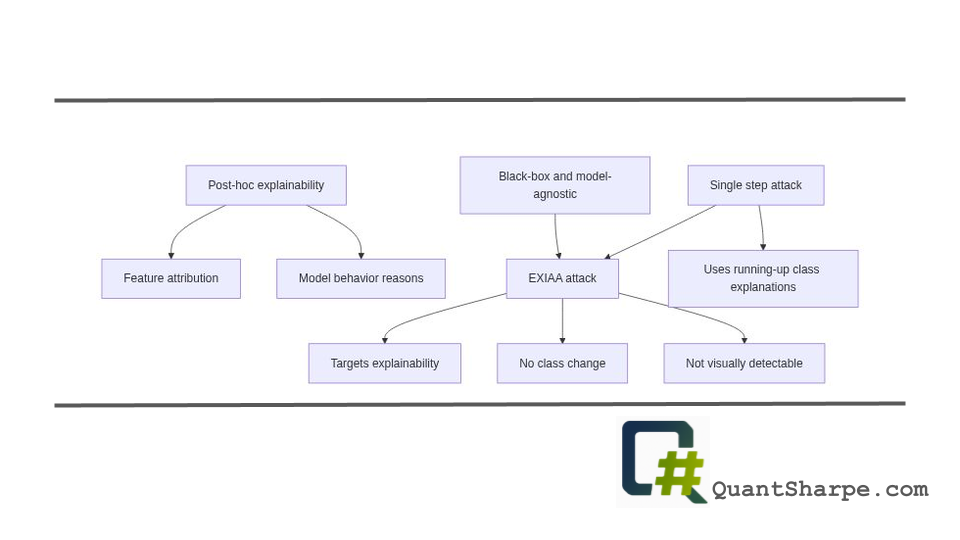
The fundamental attack mechanism is deceptively simple in its elegance. The attack operates in three phases:[3]
Phase One: Attack Image Selection — The algorithm selects an image from a different class that the model classifies with high confidence. Importantly, this is typically an image from the “running-up” class—the class the model is most confused about for the original image. This strategic selection leverages the observation that high-confidence predictions are associated with strong feature attributions, making them effective for inducing confusion in explanations.
Phase Two: Feature Extraction — The same post-hoc explainability method used on the original image is applied to the attack image. This reveals which features (pixels or regions) are most important for the attack image’s confident prediction in the target class.
Phase Three: Feature Injection — The final corrupted image is generated by selectively blending the original image with extracted features from the attack image using a weighted parameter α, applied only to the most impactful pixels.[3] A clipping operation ensures pixel values remain valid.
The result is striking: the corrupted image maintains structural similarity to the original (high SSIM scores), the model’s predicted class and confidence remain virtually unchanged, yet the explanation provided by post-hoc methods changes dramatically. In evaluations on ImageNet using ResNet-18 and ViT-B16 models, the attacks successfully altered explanations from multiple post-hoc methods including saliency maps, integrated gradients, and DeepLIFT SHAP, often with modification magnitudes measured by mean absolute difference showing substantial changes while prediction probabilities dropped by less than 5% to roughly 10%.[1][3]
Why This Matters: Implications for Trust and Safety
The significance of this vulnerability cannot be overstated. Explainability methods have become more than academic curiosities; they are embedded in regulatory frameworks, organizational auditing procedures, and high-stakes decision-making pipelines across healthcare, criminal justice, finance, and autonomous systems.
Consider a concrete scenario: A hospital deploys a deep learning model to assist in cancer detection from radiological images. The model achieves excellent diagnostic performance on validation data. To satisfy regulatory requirements and build clinician trust, the hospital implements SHAP or saliency map explanations, showing which tumor features most influenced the model’s assessment. A radiologist reviews these explanations and, finding them consistent with their clinical knowledge and intuition, gains confidence in the system’s reliability.
Now imagine an adversary—whether malicious, or simply someone seeking to demonstrate a flaw—generates an adversarially corrupted version of this image using EXIAA. The model still outputs the same diagnosis with the same confidence. The image appears visually identical under clinical inspection. But the explanation has shifted dramatically, now highlighting different regions or features as important. If a radiologist were to rely on this manipulated explanation, they might form incorrect beliefs about the model’s reasoning, potentially missing opportunities to catch systematic flaws or misuse.
This attack is particularly potent because it requires only black-box access—the attacker needs only the model’s predictions and its explanations, not its weights or architecture.[1][2] This is a dramatic reduction from previous adversarial attacks on explanations, which typically required white-box access or were limited to single-step, model-specific approaches. The single-step nature of EXIAA makes it practical and efficient.
Critical Examination: Strengths of the Research
Methodological rigor. The paper provides systematic evaluation across multiple architectures (ResNet-18 and ViT-B16), multiple post-hoc methods (saliency maps, integrated gradients, DeepLIFT SHAP), and both ImageNet and CIFAR-10 datasets. The use of SSIM to verify visual imperceptibility and careful measurement of explanation changes via mean absolute difference provides quantitative grounding.
Practical applicability. By requiring only black-box access and operating in a single step, the attack maps to real-world threat scenarios where attackers cannot access model internals. This makes the vulnerability immediately relevant to deployed systems.
Clear presentation. The paper effectively communicates the problem, method, and implications in accessible language. The three-phase attack procedure is intuitive and reproducible.
Addressing a blind spot. While adversarial robustness of model predictions has received extensive attention, adversarial robustness of explanations remained understudied. This work highlights a critical gap.
Limitations and Critical Considerations
Despite its contributions, the research has important limitations that deserve careful examination.
Domain specificity. The attack is demonstrated exclusively in the image domain using computer vision models and datasets. While the authors suggest extension to time series, text, and video, the current evidence is limited to vision. The approach may not translate straightforwardly to other modalities with different feature structures and explanation methods.
Specificity to particular explanation methods. The attack targets feature-attribution based post-hoc methods. Other explanation approaches—counterfactual explanations, prototype-based methods, or concept-activation vectors—may be inherently more or less vulnerable. The generalizability across explanation paradigms remains unclear.
Limited analysis of detection. While the attack maintains visual imperceptibility and prediction stability, the paper does not deeply explore whether domain experts examining the explanations themselves might notice anomalies or inconsistencies. In practice, a clinician or auditor might compare multiple explanation methods or analyze the spatial coherence of attributions in ways that reveal manipulation.
Prerequisite of having explanations. The attack requires access to the model’s explanations. If an organization does not compute or expose explanations (or computes them only internally for auditing), this particular attack vector is unavailable. However, this observation perhaps reflects the broader problem: we assume transparency mechanisms cannot themselves be attacked.
Limited discussion of defense mechanisms. The paper identifies the vulnerability but provides limited guidance on mitigation strategies. How should practitioners defend against explanation-based attacks? The work would be strengthened by exploring robustified explanation methods or detection approaches.
Implications for the Field
This research raises fundamental questions about the role of explainability in AI assurance.
The explainability paradox: Explainability has been positioned as a mitigation for opacity and untrustworthiness. Yet this work demonstrates that explanations themselves can be attacked and manipulated, potentially creating a false sense of security. An explanation that appears reasonable but has been adversarially manipulated may be worse than no explanation at all.
The need for explanation robustness as a first-class concern: Just as the community developed methods to detect and defend against adversarial examples targeting predictions, we must now develop approaches to assess and improve the robustness of explanations themselves. This includes both robustness metrics and hardened explanation methods.
Integration with explainability frameworks: The major machine learning explainability frameworks—from SHAP to Integrated Gradients to saliency methods—were not designed with adversarial robustness as a consideration. Future versions of these tools should incorporate robustness testing and perhaps adversarial training.
Rethinking the explainability-robustness relationship: There may be inherent trade-offs between explanation simplicity (and human interpretability) and explanation robustness. Simple explanations may be easier to manipulate. This tension deserves investigation.
Future Directions and Open Questions
The paper concludes by identifying several promising research directions.
Extension to other data modalities represents the most immediate path forward. Text, time-series, and tabular data explanations operate under different feature structures; EXIAA may need substantial adaptation. Understanding how the attack generalizes would clarify whether this is a fundamental vulnerability or one specific to vision’s spatial structure.
Advanced blending techniques such as Poisson blending or other image processing methods could potentially reduce detectability even further, making the attack more imperceptible even under close inspection.
Exploration of defense mechanisms is critical. Can explanation methods be made inherently more robust? Can we detect when explanations have been adversarially manipulated? Can we develop certified robustness guarantees for explanations, analogous to certified defenses for predictions?
Systematic evaluation of explanation robustness across methods and models could establish baselines and identify which explanation approaches are most vulnerable, guiding practitioners toward more robust techniques.
Investigation of certified explanations that provide guarantees about explanation stability under bounded perturbations represents a more ambitious future direction.
Broader Connections: The Adversarial Robustness Perspective
This work should be understood as part of the broader adversarial robustness literature, but with an important pivot: previous adversarial robustness research focused on attacking and defending predictions. This research extends that concern to explanations.
This mirrors a transition that occurred in computer security decades ago: initial security research focused on preventing unauthorized access to systems, but eventually developed more nuanced approaches to integrity (ensuring data hasn’t been modified) and provenance (understanding where data originated). Similarly, explainability research is maturing to recognize that merely providing explanations is insufficient; we must ensure those explanations are reliable.
The connection to fairness and algorithmic auditing is also noteworthy. Fairness auditing often relies on explanations and feature attributions to identify disparate impact or discriminatory patterns in model behavior.[5] If these explanations can be manipulated, the entire auditing enterprise becomes compromised. An organization could use EXIAA-style attacks to remove evidence of unfair model behavior from explanations while maintaining the same discriminatory predictions.
Conclusion
The eXIAA paper makes a vital contribution by exposing a critical vulnerability in post-hoc explainability methods that have been widely adopted as mechanisms for model auditing, regulation compliance, and trustworthiness assurance. By demonstrating that explanations can be dramatically altered without changing predictions or becoming visually detectable, Pesce, Wei, and Mengaldo challenge the implicit assumption that explanations constitute reliable insights into model behavior.
This is not an argument against explainability—quite the contrary. The work reinforces that explainability is sufficiently important that it must be robust, validated, and carefully integrated into decision-making systems. Rather than retreating from explainability, practitioners and researchers should treat explanation robustness as a first-class concern, developing methods to evaluate, improve, and defend explanations with the same rigor applied to prediction robustness.
For organizations deploying machine learning in safety-critical domains, this research should prompt reflection: Are we relying on explanations as a primary mechanism for assurance? If so, how do we know those explanations are trustworthy? What would it mean to audit the auditor—to verify that our explanation methods themselves are sound? As machine learning systems become increasingly consequential in society, these questions will only grow more urgent.