
TiDAR: Think in Diffusion, Talk in Autoregression
Introduction
This post provides an in-depth analysis of the research paper TiDAR: Think in Diffusion, Talk in Autoregression by Jingyu Liu; Xin Dong; Zhifan Ye; Rishabh Mehta; Yonggan Fu; Vartika Singh; Jan Kautz; Ce Zhang; Pavlo Molchanov. This work presents important findings that advance our understanding of the field.
TiDAR: Bridging the Speed-Quality Divide in Large Language Model Inference
Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, and Pavlo Molchanov from NVIDIA have introduced TiDAR (Think in Diffusion, Talk in Autoregression), a groundbreaking hybrid architecture that addresses one of the most persistent challenges in modern language model deployment: the fundamental tension between inference speed and output quality.[1][2] Released in November 2025, TiDAR represents a significant departure from conventional approaches, demonstrating that the long-standing speed-quality trade-off can be substantially mitigated through thoughtful architectural innovation.
The Historical Context: Where We’ve Been
To appreciate TiDAR’s significance, we must first understand the divergent paths that language model inference has followed over the past several years.
Autoregressive (AR) models, exemplified by GPT and similar architectures, generate text sequentially-one token at a time. Each new token is conditioned on all previously generated tokens through causal attention, which maintains the sequential dependencies that align naturally with how language actually unfolds. This architectural choice delivers exceptional output quality, as the model can carefully consider all preceding context before generating each token. However, this sequential nature makes autoregressive models fundamentally memory-bound during inference: the GPU must wait for one token to complete before processing the next, leaving vast computational capacity idle. In practical terms, this means generating a 100-token response might only utilize a fraction of available GPU compute, creating a significant efficiency penalty.
Diffusion language models (dLMs) emerged as a parallel alternative, generating multiple tokens simultaneously rather than sequentially. By leveraging bidirectional attention and iterative refinement, diffusion models can fill more of the GPU’s computational pipeline, achieving substantially higher throughput (tokens per second). Yet this parallelism comes with a substantial cost: diffusion models consistently produce lower-quality outputs than their autoregressive counterparts, a gap that has prevented their widespread adoption despite their efficiency advantages.[1] The quality degradation stems from the fundamental differences in how diffusion models approach text generation-they predict distributions over masked positions rather than maintaining the causal dependencies that natural language requires.
Speculative decoding represents the first major attempt to bridge this divide, where a smaller draft model quickly generates candidate tokens, and a larger model verifies them autoregressively. While this approach reduces some latency, it introduces additional architectural complexity (maintaining two models), relies on draft model quality, and often only achieves modest speedups-typically in the range of 2-3× rather than the transformative improvements the field sought.[2]
Prior hybrid approaches attempted various combinations of these paradigms, but generally fell short of providing compelling alternatives. Either they preserved the quality-speed trade-off, or they introduced such architectural complexity that deployment became impractical.
The Core Innovation: Structured Hybrid Attention Masking
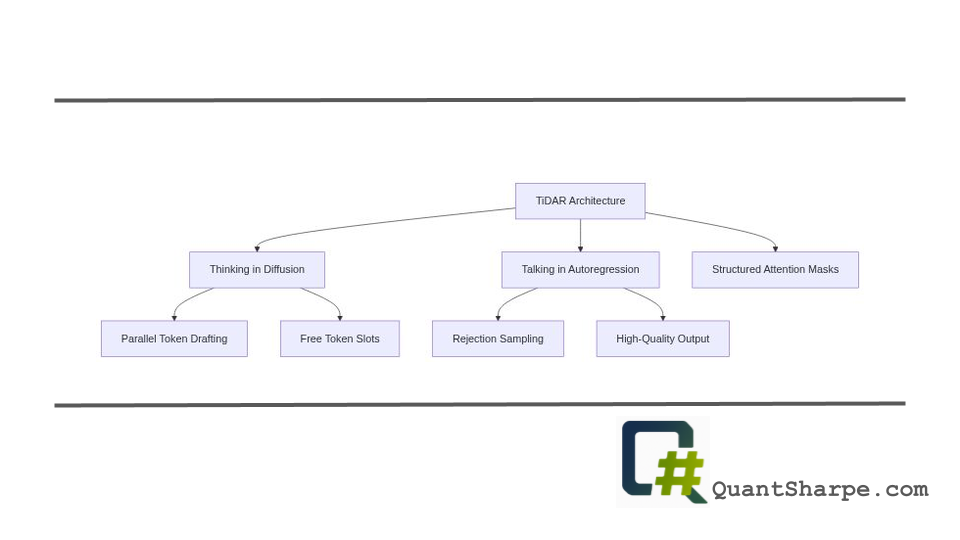
TiDAR’s breakthrough centers on a deceptively elegant design: a structured hybrid attention mask that enables the same model to simultaneously operate in both diffusion mode (for fast parallel drafting) and autoregressive mode (for quality verification) within a single forward pass.[1][3]
The architecture partitions the token sequence into three distinct regions, each governed by different attention patterns:
The prefix region contains the established context-tokens already confirmed as part of the output. These positions employ causal attention, where each token attends only to positions that precede it. This maintains the autoregressive property: the model respects the sequential dependencies essential for coherent language generation. This is the “talking” phase-generating outputs with the quality constraints of autoregressive models.[1]
The proposed region holds candidate tokens drafted in the previous generation step. These maintain the causal attention pattern from prefix tokens, ensuring consistency in how already-proposed content is processed.
The predraft region consists of masked token positions designated for the next generation step. Critically, these positions employ bidirectional attention, allowing each masked position to attend to both the prefix and other masked positions. This bidirectional structure enables the model to parallel-generate predictions for all masked locations simultaneously-this is the “thinking” phase.[1] The model can predict what should appear at multiple positions concurrently, dramatically increasing throughput.
The genius of this design lies in its exploitation of a ubiquitous but underutilized characteristic of modern GPUs: free token slots. GPUs process multiple token positions in parallel; during sequential autoregressive generation, only a single new position is computed per forward pass, leaving most of that parallel computational capacity unused. TiDAR fills these idle slots with masked positions for diffusion-based parallel prediction, achieving approximately the same latency as sequential generation while computing substantially more tokens.[5] From an efficiency perspective, it’s comparable to sitting in a car with 16 empty seats and filling those seats rather than leaving them vacant-minimal additional effort, significant throughput increase.
Training Strategy: The Full-Mask Breakthrough
Equally crucial to TiDAR’s success is its full-mask training strategy, which represents a conceptual shift in how hybrid models balance competing objectives.[1][3]
Traditional diffusion language models employ random masking strategies during training, corrupting a subset of tokens at each iteration. This approach suffers from several limitations: it creates sparse loss signals (most tokens aren’t corrupted, so their gradients don’t directly supervise diffusion loss), requires carefully tuned masking percentages to balance competing objectives, and creates train-test mismatch-the training procedure doesn’t perfectly match inference dynamics.
TiDAR’s innovation is straightforward yet powerful: mask all tokens in the diffusion section during training. Every token in predraft positions becomes a mask token, so the model receives diffusion loss signals for the entire region. This delivers three concrete benefits:
First, the loss signal becomes maximally dense. The diffusion loss term encompasses every token in the diffusion region, not just a randomly corrupted subset. This richer supervision signal allows the model to learn the diffusion task more effectively with potentially less training data or compute.[1][3]
Second, loss balancing becomes trivial. Both the autoregressive and diffusion losses operate over the sequence length, making their magnitudes naturally comparable. A single weighting factor α (typically set to 1.0) balances both objectives, eliminating the hyperparameter sensitivity that plagued prior approaches.[3]
Third, train-test consistency improves dramatically. During training, the model predicts real tokens at fully masked positions; during inference, it generates one-step predictions at masked positions with the same configuration. This alignment reduces the distribution shift between training and inference, improving generalization.[1] The model’s training experience directly mirrors what it encounters during deployment.
Self-Speculative Generation: Drafting and Verification as One
Where speculative decoding maintains separate draft and verification models, TiDAR implements self-speculative generation: the same backbone simultaneously serves as both drafter and verifier.[3]
The inference workflow unfolds elegantly across each forward pass:
The model first determines tokens within the prefix using autoregressive sampling conditioned on all established context. These tokens represent the high-quality sequential generation the model performs best at.
Simultaneously, the model uses one-step diffusion to generate candidate tokens for all masked positions in parallel. Rather than iterative diffusion refinement (which would require multiple forward passes), these candidates are produced in a single step by predicting the distribution over each masked location given the prefix and other masked positions.
The final sampling process employs rejection sampling, where the autoregressive mode verifies diffusion-proposed candidates. If an autoregressive prediction for a position aligns sufficiently with what the diffusion mode proposed, that candidate is accepted; otherwise, it’s rejected and the autoregressive prediction is used instead.[3] This verification ensures that regardless of which generation mode proposed a token, the final output respects autoregressive quality standards.
Critically, this entire workflow-drafting, proposing, verifying, and sampling-occurs within a single forward pass. The model doesn’t require separate forward passes for different components, unlike speculative decoding. This architectural efficiency translates directly to throughput improvements.[1]
Technical Optimizations: Exploiting Modern Hardware
TiDAR incorporates several hardware-aware optimizations that deserve attention, as they exemplify a broader trend toward explicit co-design of algorithms and hardware:
Exact KV Cache Reuse: During inference, the key-value matrices computed for prefix tokens can be precisely reused across forward passes because these positions maintain causal attention.[1] Since causal tokens don’t change semantically between steps, their cached representations remain valid. This differs from diffusion models’ bidirectional attention, where positions can attend to future contexts that change as generation progresses, invalidating caches. TiDAR’s reuse eliminates redundant computation, improving practical efficiency beyond theoretical throughput metrics.
Memory-Efficient Attention Mask Management: The model pre-initializes structured attention masks and reuses them by slicing, rather than reconstructing masks at each forward pass.[1] This reduces memory overhead and CPU-GPU communication costs.
Dense Compute Utilization: By explicitly designing the architecture to fill free GPU token slots, TiDAR maximizes compute density-the ratio of useful computation to total GPU capacity. This represents a philosophical shift: rather than asking “how can we optimize algorithms for their own sake,” the research asks “how can we better utilize the hardware we already have?” This pragmatic perspective increasingly dominates efficiency research in LLMs.[1]
Empirical Performance: Quantifying the Improvements
TiDAR’s performance improvements are substantial and well-validated across multiple benchmarks and model scales:
Throughput Improvements: TiDAR achieves 4.71× to 5.91× speedup in tokens per second compared to standard autoregressive models.[3] For the 1.5B parameter scale, this speedup is achieved with lossless quality compared to the AR baseline. For the 8B parameter scale, minimal quality loss accompanies the 5.91× speedup, representing an exceptional efficiency-quality frontier.[2]
Comparative Advantages: Against pure diffusion models (Dream, Llada), TiDAR outperforms both in efficiency and quality, even when those diffusion models are optimized for accuracy through multiple refinement steps.[5] Against speculative decoding approaches, TiDAR’s parallel drafting and unified backbone outcompete traditional two-model approaches in measured throughput and quality.[2]
Generalization Across Tasks: Evaluation covers both generative tasks (standard next-token prediction) and likelihood tasks (computing model probabilities for arbitrary text sequences). This breadth is important because likelihood computation is essential for applications like ranking, scoring, and probabilistic inference, domains where diffusion models historically struggle due to their bidirectional attention incompatibility with causal likelihood evaluation.[1] TiDAR handles both with comparable efficiency.
Scalability: Testing at both 1.5B and 8B parameter scales demonstrates the approach’s scalability, suggesting applicability to larger models currently dominating practical deployment.[3]
Critical Examination: Strengths and Limitations
TiDAR represents a substantial advance, but understanding both its genuine strengths and its remaining limitations provides valuable perspective:
Strengths:
The architectural elegance of structured hybrid attention masks is a genuine innovation. Rather than bolting together existing components (as speculative decoding does), TiDAR reimagines the token generation process from first principles, creating a unified framework where diffusion and autoregression operate synergistically rather than sequentially.
The hardware-aware design philosophy reflects mature understanding of modern GPU characteristics. As models scale, memory bandwidth increasingly constrains inference rather than compute capacity. TiDAR explicitly addresses this reality rather than ignoring it, providing a template for future efficiency work.
The training efficiency is notable. By using both autoregressive and diffusion losses on identical training data through a single structured attention mask, the approach avoids the computational overhead of maintaining separate models or specialized training pipelines. Continual pretraining from existing checkpoints (Qwen2.5, Qwen3) demonstrates practical applicability.
The breadth of evaluation strengthens confidence in the results. Inclusion of likelihood tasks, not just generation tasks, proves the approach’s versatility across application domains.
Limitations and Open Questions:
The quality-speed trade-off still exists, though reduced: While TiDAR achieves impressive speedups with minimal quality loss at smaller scales (1.5B with lossless quality), larger scales (8B) show meaningful quality degradation despite the 5.91× speedup.[2] The research doesn’t fully explain whether this reflects fundamental limitations or simply represents the current point on the efficiency frontier. Scaling to 70B+ parameter models may reveal tighter constraints.
Limited architectural flexibility: TiDAR’s design depends heavily on structured attention masks and the specific partition of tokens into prefix, proposed, and predraft regions. It’s unclear how sensitive performance is to these choices or whether alternative partitioning strategies might yield further improvements. The research provides ablations on masking strategies but not on fundamental architectural variations.
Inference-time hyperparameter dependence: While the research claims “no inference-time hyperparameters to tune,” the sampling process offers choices between “trusting AR predictions” or “trusting diffusion predictions” for verification, which implicitly represent different operating points on the quality-speed frontier.[3] Different applications may require different choices, introducing practical complexity.
Comparison fairness questions: The speculative decoding and diffusion model baselines may not represent optimal implementations. Whether the improvements reflect architectural advantages or simply superior engineering requires careful interpretation.[2][4]
Limited analysis of failure modes: When does TiDAR’s hybrid approach fail? The research doesn’t thoroughly characterize scenarios where the diffusion-AR verification mismatch produces degraded outputs or where one mode substantively conflicts with the other. Understanding these failure modes is essential for production deployment.
Implications and Broader Connections
TiDAR’s contributions extend beyond its specific technical innovations into broader implications for language model research:
The Paradigm Shift Toward Hardware-Algorithm Co-Design: For years, LLM research primarily optimized algorithms in isolation, assuming hardware deployment as a secondary concern. TiDAR exemplifies an emerging counter-trend: designing algorithms with explicit awareness of hardware constraints and characteristics. This perspective recognizes that GPU architecture has stabilized somewhat; future gains increasingly come from better utilizing existing hardware rather than waiting for architectural breakthroughs. This philosophy will likely influence future research directions.
Hybrid Architectures as First-Class Citizens: Historically, researchers viewed hybrid approaches as compromises-second-best solutions when pure approaches failed. TiDAR reframes hybrids as potentially superior to pure approaches through synergistic combination rather than mere concatenation. This legitimizes hybrid methods as primary research directions rather than fallbacks.
The Importance of Structured Inductive Biases: The structured attention mask mechanism represents an explicit inductive bias reflecting our understanding of language generation. Rather than relying on the model to discover optimal computation patterns through scaling and training, TiDAR bakes in principled structure. This contrasts with the scaling-centric philosophy dominating recent LLM research and suggests value in reintroducing thoughtful architectural constraints.
Toward Task-Aware Generation: The flexibility to “trust AR” or “trust diffusion” predictions depending on task characteristics hints at future directions where models adaptively adjust generation strategies. Math benchmarks might benefit from diffusion proposals, while coding tasks might prefer AR guidance. This adaptive approach remains largely unexplored.
Future Research Directions
Several promising extensions to TiDAR’s framework merit investigation:
Adaptive Token Masking: Rather than fixed predraft regions, could the model dynamically determine how many tokens to draft based on confidence signals? High-confidence prefixes might justify larger draft regions, while uncertain contexts might reduce drafting. This adaptive strategy could further optimize the efficiency-quality frontier.
Multi-Scale Hybrid Generation: Could TiDAR extend to hierarchical generation where different abstraction levels (tokens, phrases, sentences) employ different generation modes? Sentences might be drafted diffusively, then tokens refined autoregressively.
Integration with Retrieval Mechanisms: Would combining TiDAR’s parallel drafting with retrieval-augmented generation improve quality while maintaining speed? Diffusion drafting could propose candidates that retrieval then evaluates.
Cross-Model Distillation: Can smaller TiDAR models effectively distill from larger pure AR models, leveraging the hybrid structure to capture quality while maintaining efficiency gains?
Likelihood and Ranking Applications: Given TiDAR’s efficiency at likelihood computation, extensive evaluation on ranking, reranking, and scoring tasks could reveal killer applications where the architecture’s advantages become decisive.
Conclusion: A Maturing Field
TiDAR represents more than an incremental efficiency improvement; it exemplifies a maturing phase in language model research where fundamental trade-offs yield to thoughtful architectural innovation. By recognizing that speed and quality need not be mutually exclusive-that apparent dichotomies often reflect insufficient architectural creativity rather than fundamental constraints-the research opens new research directions.
The achievement of 4.71× to 5.91× speedup while maintaining autoregressive-level quality closes a gap that has constrained language model deployment for years. For applications prioritizing latency alongside quality, TiDAR provides a compelling solution. More broadly, it demonstrates that the efficiency frontier in LLMs remains rich with opportunity for those willing to challenge conventional assumptions about generation mechanisms.[1][2][3]
As large language models continue scaling and deployment challenges intensify, TiDAR’s explicit attention to hardware characteristics, its unified framework for combining generative paradigms, and its demonstration that architectural innovation remains impactful provide a template for future efficiency research. The field is increasingly learning that genuine breakthroughs don’t require waiting for better hardware-they require better thinking about how to use the hardware we have.
References
This post is based on: TiDAR: Think in Diffusion, Talk in Autoregression by Jingyu Liu; Xin Dong; Zhifan Ye; Rishabh Mehta; Yonggan Fu; Vartika Singh; Jan Kautz; Ce Zhang; Pavlo Molchanov