
From Black-box to Causal-box: How Researchers Are Building Models That Can Explain Their 'What If' Reasoning
From Black-box to Causal-box: How Researchers Are Building Models That Can Explain Their “What If” Reasoning
Understanding why a deep learning model made a particular decision remains one of the most pressing challenges in artificial intelligence, particularly when those decisions affect human lives. A recent paper from researchers at Columbia University’s Causal Artificial Intelligence Lab, Inwoo Hwang, Yushu Pan, and Elias Bareinboim, tackles this problem from a fundamentally new angle. Their work, titled “From Black-box to Causal-box: Towards Building More Interpretable Models,” introduces the concept of causal interpretability as a formal framework for determining when models can reliably answer counterfactual questions, the hypothetical “what if?” scenarios that form the backbone of human reasoning and explanation.[1][2] Rather than asking whether a model’s predictions match human intuition or whether we can visualize its decision boundaries, this research asks a more rigorous question: Can a model’s predictions behave coherently and consistently when we ask it to imagine alternative scenarios?
Historical Context: The Evolution of Interpretability
To appreciate the significance of this work, it helps to understand how we arrived at this moment in machine learning research. The field of interpretability has its roots in statistics and classical machine learning, where interpretability was almost synonymous with simplicity. Linear regression models with human-readable coefficients, decision trees whose splits could be traced manually, and rule-based systems all offered transparency, you could understand exactly how input features mapped to predictions. This interpretability came at a cost: these models were often less accurate than more complex alternatives.
The rise of deep learning in the early 2010s created a crisis of interpretability. Neural networks achieved remarkable performance on image recognition, natural language processing, and other complex tasks, but their decision-making processes became increasingly opaque. A 32-layer convolutional neural network might classify medical images with superhuman accuracy, yet explaining why it flagged a particular region as cancerous proved extraordinarily difficult.
This gap between performance and interpretability sparked the field of Explainable AI (XAI). Researchers developed techniques like saliency maps, attention visualizations, LIME (Local Interpretable Model-agnostic Explanations), and SHAP (SHapley Additive exPlanations) values. These methods offered ways to understand model behavior by approximating how input features influenced predictions. However, as Bareinboim and colleagues have been arguing for several years, these techniques operate primarily at the correlational level. They tell us which features the model associates with particular outputs, but they don’t necessarily tell us about causal relationships or whether the model’s suggestions would actually change outcomes if we intervened on the world.
Consider a loan approval model that heavily weights income in its decisions. A saliency map might show that higher income correlates with loan approval. But this doesn’t mean the model understands that earning more would actually cause an application to be approved, it might simply be reflecting a historical pattern where both income and creditworthiness were correlated because of common causes like education or job stability. The model lacks causal structure.
The Problem with Existing Approaches
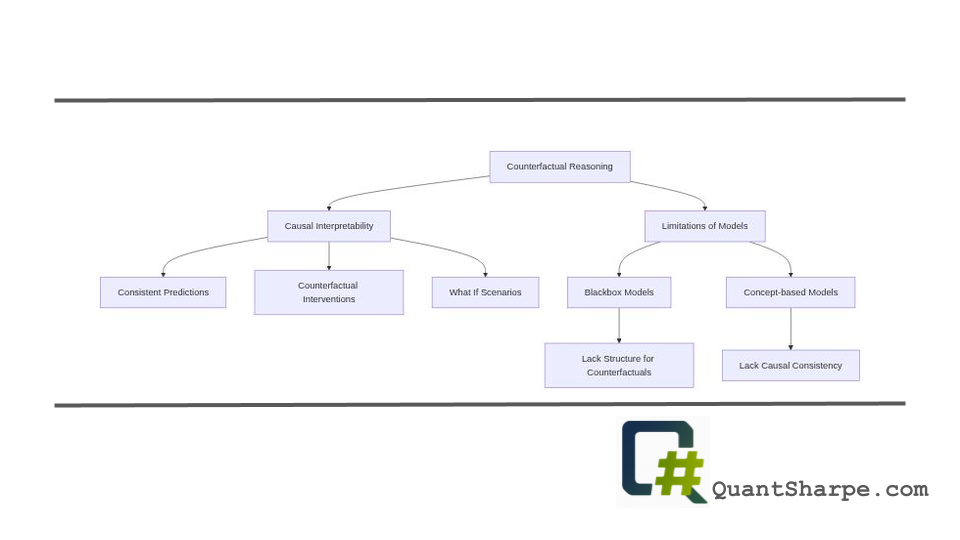
The paper identifies a fundamental limitation in two of the most common architectural paradigms in machine learning: blackbox models and concept-based models.[2]
Blackbox predictors represent the dominant paradigm in modern deep learning. These models map inputs directly to outputs, pixels to image labels, tokens to next-word predictions, patient histories to disease risk scores. They achieve remarkable predictive accuracy but fundamentally lack the internal structure needed to answer counterfactual questions. If you ask a pure blackbox model “What would change if this pixel had a different value?” or “Would this diagnosis have changed if the patient were younger?”, there is no principled mechanism for answering these questions from observational data alone. The model simply doesn’t encode the causal relationships between variables.
Concept-based models seemed like they might solve this problem. These architectures first learn interpretable features (concepts) and then make predictions based on these concepts rather than raw inputs. By adding this intermediate layer of human-comprehensible features, researchers hoped to gain both interpretability and the ability to reason causally. But here’s where the Hwang, Pan, and Bareinboim framework delivers a surprising negative result: concept-based models are also not guaranteed to be causally interpretable in general.[2] Using interpretable features is helpful, but it doesn’t automatically ensure that a model can answer counterfactual queries consistently.
Causal Interpretability: Reframing the Problem
Rather than asking “Can I understand this model?” the authors ask a more precise question: “Can this model answer counterfactual queries consistently?” A model class is formally defined as causally interpretable if every model within that class produces consistent predictions under counterfactual interventions based on observational data.[2] This is not about transparency of parameters or visualizability of features. It’s about whether the model encodes causal structure in a way that allows it to reason about “what if” scenarios reliably.
To make this concrete, consider a medical diagnosis scenario. Suppose we have observational data where patients who received treatment X showed better outcomes, and we’ve built a model that predicts treatment efficacy. For this model to be causally interpretable regarding the question “Would the diagnosis have changed if a different treatment had been administered?”, the model must be able to answer this counterfactual query in a way that’s consistent with the underlying causal structure. Different models might have different parameterizations, but if they’re all based on the same causal assumptions, they should agree on counterfactual predictions.
The framework employs structural causal models as its formal foundation, using causal diagrams to represent which variables causally influence which other variables. This mathematical representation allows the researchers to derive a complete graphical criterion that determines whether a given model architecture can actually support a given counterfactual query.[2] This is powerful because it moves from informal intuitions about interpretability to a testable, formal specification.
Deep Analysis: The Fundamental Tradeoff
Perhaps the most significant contribution of this work is the identification and characterization of a fundamental tradeoff between causal interpretability and predictive accuracy.[1][2] This insight deserves careful attention because it implies that we cannot simply add causal structure to any model without consequences.
The researchers discovered that concept-based models using all observed features for prediction typically cannot achieve causal interpretability. However, by constraining these models to use only a carefully selected subset of features, causal interpretability can be recovered. The trade-off emerges here: this constraint improves causal consistency but may reduce the model’s predictive expressiveness.
The paper goes further by characterizing the unique maximal set of features that preserves causal interpretability while maintaining the highest possible predictive power.[1][2] This is not a heuristic approximation but a theoretically justified characterization. The practical implication is profound: for a given causal structure and a specific counterfactual query, there exists an optimal feature set. Include features beyond this set and you lose causal interpretability; exclude features within this set and you unnecessarily sacrifice predictive accuracy.
This tradeoff is neither surprising in retrospect nor trivial in practice. It explains why simpler, more interpretable models often generalize better and why adding complexity doesn’t always improve performance, there’s a structural reason rooted in causal identifiability. But it also suggests that practitioners operating in high-stakes domains need not accept the traditional choice between “accuracy and interpretability.” Instead, they can identify where their particular application falls on this tradeoff curve and optimize accordingly.
Strengths of the Framework
The work possesses several methodological strengths that elevate it above much of the interpretability literature.
First, formal rigor and theoretical completeness: Rather than proposing heuristics or intuitions, the paper provides formal definitions, theorems, and graphical criteria. The notion of causal interpretability is mathematically precise, and the graphical criterion is complete, meaning it fully characterizes when counterfactual queries can be answered. This formality enables other researchers to build on these results and extends the work beyond a single application domain.
Second, the framework does not require complete causal knowledge: A practical limitation of many causal approaches is that they demand a fully specified causal graph, including difficult-to-measure confounders. The authors show that their framework “does not require full specification of the causal graph or modeling of unobserved confounders; it only involves the descendants of the target features in the counterfactual query.”[2] This dramatically increases the feasibility of applying the framework to real-world problems where complete causal knowledge is rarely available.
Third, negative results with positive implications: The paper doesn’t just say “interpretability is hard”, it explains why blackbox and concept-based models fail and what structure is needed to succeed. This negative characterization is actually constructive because it points researchers toward solutions.
Fourth, empirical validation: The theoretical findings are supported by experimental results that corroborate the proposed framework, demonstrating that the theory translates to practice.
Critical Examination: Limitations and Open Questions
Despite its strengths, the framework has several limitations worth considering critically.
Dependence on causal assumptions: The framework is only as good as the causal model it’s based on. In practice, specifying causal relationships is challenging, subjective, and sometimes contentious. The authors claim their approach doesn’t require full causal specification, but it does require correct identification of which variables are causal ancestors of the target variable. If these assumptions are wrong, the framework breaks down. The paper doesn’t deeply explore how robust the approach is to misspecified causal graphs or provide guidance on validating causal assumptions empirically.
Scalability to high-dimensional domains: Most interpretability research focuses on domains with relatively modest numbers of features. How does the framework scale to domains with thousands or millions of features? Finding the “maximal interpretable feature set” could become computationally intractable. The paper includes experiments but doesn’t thoroughly explore computational complexity or approximation strategies for high-dimensional settings.
Validation of counterfactual predictions: How do we know whether a model’s counterfactual predictions are actually correct? In observational data, counterfactual ground truth is inherently unavailable, that’s the whole point of counterfactuals. The paper doesn’t extensively address validation strategies. In practice, practitioners might use domain expert judgment, small-scale interventional experiments, or simulation, but the paper leaves many validation questions open.
Limited discussion of multi-level causal inference: Many real-world applications involve hierarchical structures (patients nested within hospitals, individuals nested within communities). The paper doesn’t extensively discuss how the framework applies to such settings or how intermediate levels of aggregation interact with causal interpretability.
Practical guidance for model designers: While theoretically rigorous, the paper leaves open the question of how practitioners should use these insights in practice. Given a domain and a counterfactual query, what’s the practical workflow for identifying the interpretable feature set and building a model that’s both accurate and interpretable? More concrete guidance and toolkits would strengthen the practical impact.
Implications for High-Stakes Applications
The work has particularly important implications for domains where both accuracy and explainability are critical. In healthcare, machine learning models increasingly support clinical decision-making, yet physicians and patients need to understand why particular diagnoses or treatment recommendations were made. Causal interpretability directly addresses this need: a model that can answer “Would the diagnosis have changed if the patient’s biomarker were X?” provides actionable insight beyond predictions alone.
In criminal justice, predictive risk assessment models influence bail decisions and sentencing recommendations. Defendants and their advocates have legal and ethical rights to understand how these models work and what factors influenced specific decisions. A causally interpretable model framework could support more defensible and fair decision-making processes.
In financial services, loan approval models must comply with fair lending regulations that often have a causal flavor: lenders cannot make decisions based on protected characteristics even indirectly. Causal interpretability provides a principled way to verify that protected variables don’t causally influence decisions, rather than just checking surface-level feature lists.
Future Directions
Several natural extensions of this work merit exploration.
Dynamic and temporal causal models: Most of the framework assumes a static setting where causal relationships don’t evolve. Many real systems are inherently temporal, with causal relationships changing over time. Extending causal interpretability to temporal and sequential decision-making remains an open frontier.
Causal discovery integration: Rather than assuming a causal graph, could the framework be combined with causal discovery algorithms to jointly learn structure and build interpretable models? This might automate the process of identifying the interpretable feature set.
Robustness and sensitivity analysis: Relaxing the assumption that the causal model is perfectly specified, how sensitive are the counterfactual predictions to small changes in causal relationships? Understanding this sensitivity would be valuable for practitioners.
Interactive interpretability: Could causal interpretability be integrated with interactive machine learning systems where users can ask follow-up questions and the system refines its explanations? This could make the framework more practical for end users.
Fairness and causal interpretability: While the authors mention fairness applications, more explicit integration of fairness constraints with causal interpretability could yield powerful approaches to building fair and interpretable models simultaneously.
Benchmark datasets and evaluation metrics: The field would benefit from standardized benchmarks specifically designed to evaluate causal interpretability, analogous to how ImageNet revolutionized computer vision evaluation.
Broader Connections in the Field
This work sits at an intersection of several vibrant research areas.
With respect to causal inference, it builds on foundational work by Judea Pearl on causal graphs and do-calculus, extending these concepts into the machine learning domain. The connection to Pearl’s work on the “Causal Hierarchy”, distinguishing association, intervention, and counterfactuals, is explicit and deep. Rather than treating causal inference and machine learning as separate fields, this work shows how causal structure enriches machine learning.
For explainable AI, the paper moves beyond local explanations and feature importance scores toward a more structural understanding. While SHAP values and LIME provide correlational explanations, causal interpretability asks for causal ones. This suggests that the next generation of XAI methods should incorporate causal reasoning.
In the context of human-AI interaction, causal interpretability provides a foundation for more meaningful human-AI collaboration. When humans can ask “what if” questions and receive reliable answers grounded in causal understanding, the interaction becomes more productive and trustworthy.
The work also connects to transfer learning and domain adaptation: models that encode causal structure might be more robust to distribution shifts because they capture the mechanism generating outcomes, not just statistical correlations. A causally interpretable model trained in one setting might transfer better to new settings.
Conclusion
“From Black-box to Causal-box” represents a significant step forward in formalizing what it means for machine learning models to be interpretable in a deep, causal sense. By introducing the notion of causal interpretability and providing graphical criteria for determining when models can reliably answer counterfactual questions, the authors move interpretability from an informal aspiration to a formal, testable property.[1][2]
The identification of a fundamental tradeoff between causal interpretability and predictive accuracy is itself a major theoretical contribution, reframing the discussion from “how can we have both accuracy and interpretability?” to “where on the tradeoff curve should we operate for our particular application?” This more nuanced framing better reflects the real constraints that practitioners face.
The work leaves several important questions for future research, particularly around validation, scalability, and practical implementation, but it provides a solid theoretical foundation and suggests concrete directions for progress. As machine learning systems increasingly influence consequential decisions about healthcare, justice, finance, and other high-stakes domains, frameworks like this become not just academically interesting but socially necessary.
Researchers and practitioners working on interpretability, causal inference, fairness, and high-stakes AI applications should engage deeply with this framework. The shift from black-box to causal-box thinking may well become foundational to next-generation approaches in explainable artificial intelligence.
References
This post is based on: From Black-box to Causal-box: Towards Building More Interpretable Models by Inwoo Hwang; Yushu Pan; Elias Bareinboim