
Agentic Refactoring: Understanding How AI Agents Transform Software Maintenance
Agentic Refactoring: Understanding How AI Agents Transform Software Maintenance
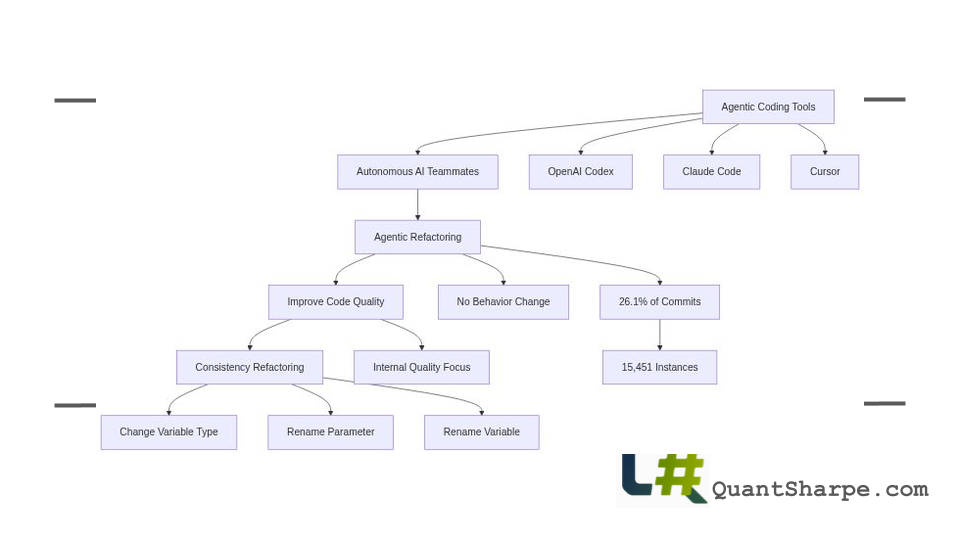
In a landmark empirical study, researchers Kosei Horikawa, Hao Li, Yutaro Kashiwa, Bram Adams, Hajimu Iida, and Ahmed E. Hassan conducted a comprehensive analysis of how artificial intelligence coding agents perform code refactoring in real-world software projects. This research, presented as “Agentic Refactoring: An Empirical Study of AI Coding Agents,” provides crucial insights into the emerging role of autonomous AI systems in software maintenance, an area that has received surprisingly little empirical scrutiny despite rapid tool adoption. By examining 15,451 refactoring instances across open-source Java projects, the authors offer evidence-based perspectives on what AI agents actually accomplish during refactoring work and how their approaches differ fundamentally from human developers.
The Historical Evolution of Refactoring and Automation
To properly contextualize this research, we must recognize that code refactoring has long been recognized as one of software engineering’s most critical, yet most challenging, practices. The formal concept of refactoring emerged prominently through Martin Fowler’s seminal 1999 work, which established refactoring as the disciplined process of improving code structure without changing external behavior. This innovation represented a philosophical shift: recognition that maintaining code quality requires ongoing attention to internal design, not merely functional correctness.
For decades, refactoring remained an inherently manual activity requiring deep domain knowledge, intimate familiarity with system architecture, and careful consideration of how changes propagate through interconnected components. The risks were substantial. Improper refactoring can introduce bugs, break existing tests, and destabilize systems in ways that may not immediately manifest. Recognizing these challenges, researchers developed increasingly sophisticated approaches, methods to identify appropriate refactoring locations, systems to recommend specific refactoring actions, and automated tools for particular classes of transformations.
However, these earlier automation attempts remained constrained by their specificity. They could reliably handle narrow refactoring categories like variable renaming or method extraction, but struggled with complex transformations requiring architectural understanding. The arrival of sophisticated language models introduced new possibilities: systems capable of understanding code semantics across entire projects, reasoning about design patterns, and proposing transformations that considered broader architectural implications.
The emergence of agentic coding tools represents the next frontier. Unlike static analysis tools or even earlier generations of AI-powered code assistants, agentic systems can plan multi-step refactoring campaigns, execute them iteratively, verify results through testing, and adapt based on feedback from the development environment. This capability transforms refactoring from an activity that individual developers must carefully orchestrate into a potential collaborative activity where human expertise guides autonomous execution.
Understanding the Research: Methodology and Scope
The empirical study examined refactoring activity across a curated dataset derived from real-world open-source Java projects, capturing the breadth of how AI agents actually behave when tasked with code improvement. The researchers employed a rigorous filtering process to focus on substantive software systems rather than educational repositories, ensuring that findings reflected genuine production-level refactoring challenges.
This methodological approach proves particularly valuable because it moves beyond anecdotal observations or controlled laboratory experiments. Rather than testing agents on artificial code samples designed specifically for evaluation, the study analyzed actual refactoring changes made by AI agents in established projects with complex architectures, existing technical debt, and real-world maintenance challenges. This grounding in authentic development contexts makes the findings more broadly applicable and trustworthy.
The empirical findings reveal a striking pattern: refactoring appears in 26.1% of AI-generated commits, a surprisingly high frequency that suggests agents recognize code quality concerns and attempt to address them proactively. This prevalence demonstrates that refactoring is not merely an incidental byproduct of feature development but a substantive component of agent behavior, a baseline finding essential for understanding whether agentic refactoring represents genuine contribution to software maintenance.
Key Findings: What AI Agents Actually Do
The research uncovers a nuanced picture of agentic refactoring that challenges some assumptions about AI capabilities while validating others. Perhaps most striking is the stark difference between where agents concentrate their efforts and where human developers focus during refactoring work.
The Low-Level Preference
Agents and humans share focus on certain operations at the lowest abstraction level, with identical top-three operations: Change Variable Type (11.8%), Rename Parameter (10.4%), and Rename Variable (8.5%). These consistency-oriented edits, addressing naming conventions, type annotations, and minor structural adjustments, represent straightforward transformations where AI can apply rules consistently across large codebases without requiring deep contextual reasoning.
However, divergence becomes apparent at higher abstraction levels. Agents show stronger preferences for Rename Attribute (6.0%) and Change Method Access Modifier (3.8%), indicating a focus on modifying class-level state and visibility. This pattern reveals something important about agent reasoning: they gravitate toward local, well-bounded changes that can be analyzed within restricted scopes, rather than transformations requiring comprehensive understanding of how system components interact.
The Motivation Landscape
What drives agentic refactoring decisions? The research shows that agents overwhelmingly prioritize internal quality concerns: maintainability accounts for 52.5% of motivations, while readability represents 28.1%. This concentration suggests that agents recognize quality metrics algorithmically, detecting long methods, duplicated code, unused imports, but lack the nuanced understanding human developers possess about which quality improvements genuinely matter for a specific system’s maintenance burden.
This observation carries practical significance. A method can be shortened through extraction, improving readability metrics, yet the extraction pattern might not match domain semantics or existing conventions. A variable can be renamed for consistency, yet might conflict with established local terminology. Agents optimize for measurable metrics without necessarily improving the experiential quality developers encounter during maintenance work.
Quality Metrics and Their Limitations
When examined through structural code metrics, agentic refactoring demonstrates measurable improvements. Class Lines of Code decrease by a median of 15.25, Weighted Method Complexity (WMC) drops by 2.07, and coupling metrics show reduction. These improvements appear statistically significant and suggest that agent-performed refactoring does reduce certain forms of complexity.
Yet here lies a crucial caveat: while structural metrics improve, the overall count of design and implementation smells shows minimal reduction. This disconnect reveals a fundamental limitation in current agentic refactoring. Design smells, patterns like Long Parameter List, Primitive Obsession, or Feature Envy, represent higher-order structural problems that require understanding how code reflects domain concepts and user intentions. AI agents excel at applying syntactic transformations while struggle with semantic refactoring that requires knowing why a particular structure exists and what purpose it serves.
Medium-Level Refactoring as Sweet Spot
The research identifies an important nuance: quality improvements are largest for medium-level refactorings, modest for low-level edits, and minimal for high-level signature-only changes. This finding suggests a bandwidth of effectiveness: agents perform best when refactoring operations require moderate complexity, enough to justify automated assistance but not so complex that they demand architectural understanding. Method extraction, parameter type changes, and similar medium-level operations yield consistent improvements, while truly transformative refactorings demand human direction.
Practical Experience: When Agents Help and When They Hinder
Beyond the statistical analysis, practitioner experience provides revealing context about agentic refactoring limitations. Early adopters report that agent performance correlates strongly with task specificity and clarity. Narrow, well-defined refactoring requests, “Rename this method in this file” or “Break this method into smaller methods”, succeed reliably, particularly when using Claude 3.5 Sonnet over GPT-4o models. However, broad requests like “Refactor this complex codebase” frequently fail, with agents becoming confused by conditional logic, long methods with multiple concerns, or code that slightly deviates from standard patterns.
This pattern reveals something crucial about current agent capabilities: they function effectively within constrained problem spaces where the solution space can be reasonably explored. When developers can reason about changes in their heads easily, agents typically can as well. When problems become genuinely complex, agents struggle, sometimes generating so many contradictory changes that they cannot escape the resulting tangled state.
An important practical observation emerges: for straightforward refactorings where dedicated tools exist, instructing an agent often consumes more time than manual execution. An experienced developer removing unused namespaces through keyboard shortcuts might complete the task in seconds, while an agent attempting the same operation could become confused and remove correct imports from wrong files, requiring extensive manual correction.
Implications for Software Development Practice
These empirical findings carry significant implications for how development teams should approach agentic refactoring integration.
Human Oversight Remains Non-Negotiable
The research and practitioner experience converge on one point: meaningful progress requires human engineers maintaining control of the workflow. Developers cannot simply unleash agents and trust the results; instead, the most effective approach follows a Test-Commit-Revert (TCR) cycle with small incremental steps. After each agent action, developers must run tests, review changes, and either commit or revert before proceeding. This cycle prevents the compounding chaos of multiple failed changes and maintains system stability.
An emerging best practice involves a surgical approach: rather than asking agents to broadly refactor code, developers request refactoring recommendations upfront, then instruct the agent to implement only those recommendations that human expertise confirms add design value. This method leverages agent analytical capabilities for identification while reserving judgment about implementation to experienced developers.
Task Granularity Matters Enormously
The effectiveness difference between narrow and broad refactoring requests suggests that agentic tools work best when problems are carefully decomposed. Rather than “refactor this service,” the instruction might become “extract this cohesive functionality into a separate method” or “create a builder pattern for this complex object.” This decomposition requires developer expertise to identify the right problem granularity, substantial cognitive work that differentiates productive agentic use from costly tool mismanagement.
Architectural Knowledge Remains Essential
The limited success of agents in eliminating design smells underscores that genuine architectural improvement requires knowledge of domain semantics, system history, and strategic direction. Agents can help eliminate technical debt through tactical refactoring, but transformations that reflect changing architectural understanding require human architects. This distinction means organizations should view agentic refactoring as complementing human architectural thinking, not replacing it.
Critical Examination: Strengths and Limitations of the Research
This empirical study makes important contributions by grounding agentic refactoring evaluation in real-world code and providing statistical rigor. The large dataset of 15,451 refactoring instances across diverse projects and the systematic filtering approach provide a solid empirical foundation. The comparison between agent and human refactoring patterns reveals genuine differences in how autonomous systems approach code quality, moving beyond speculation into evidence.
However, several limitations warrant acknowledgment. First, the focus on Java projects, while practically justified, limits generalizability. Different languages have different refactoring idioms, and agents trained primarily on Python or JavaScript might exhibit different patterns. Second, the study captures AI agent behavior at a particular moment in technological development; as language models improve, agent refactoring capabilities will likely advance, potentially shifting the findings.
Third, the analysis of design smells relies on detection heuristics, which themselves contain assumptions about what constitutes problematic structure. An agent might genuinely improve design in ways that existing smell detectors fail to recognize. Fourth, the research cannot fully distinguish between agent limitations and architectural inadequacies in the underlying projects. Some design smells might persist because fixing them would require changes violating other architectural constraints.
Additionally, the study examines agent behavior without extensive integration with human guidance. More sophisticated human-in-the-loop approaches, where humans explicitly direct agent attention toward specific design challenges, might achieve different results than analyzing agents operating with general refactoring instructions.
Future Directions: Evolution of Agentic Refactoring
As AI coding agents mature, several evolution pathways appear promising. Specialized agent architectures designed specifically for refactoring work could incorporate deeper domain modeling and architectural reasoning, moving beyond general-purpose language models toward systems that understand particular domains’ refactoring challenges. Human-agent collaboration frameworks that more tightly integrate developer expertise with agent analytical capabilities could overcome current limitations by combining agent pattern recognition with human design judgment.
Temporal reasoning represents another frontier. Current agents operate within relatively static code snapshots, but software systems evolve. Agents capable of understanding a system’s architectural evolution, how it reached current structure and why, might suggest refactorings that align with long-term strategic direction rather than local metrics optimization.
Cross-project learning offers additional potential. Rather than agents reasoning about individual projects in isolation, systems that learn refactoring patterns across ecosystems could apply proven transformations from one codebase to similar problems in others, extending collective knowledge across development communities.
Integration with code review workflows could position agentic refactoring as a formal step in development processes. Rather than agents autonomously applying changes, they might generate refactoring proposals evaluated through existing review processes, leveraging team expertise while benefiting from agent analysis.
Broader Connections: Agentic Refactoring in the Software Quality Ecosystem
This research connects to several broader conversations shaping software engineering’s future. The emergence of autonomous code agents raises fundamental questions about knowledge distribution in development teams. When agents handle routine refactoring, do developers gain or lose architectural understanding? If agents consistently improve certain metrics, do teams become overconfident in metric-driven improvement?
The research also illuminates tensions between efficiency and intentionality in software development. Agents dramatically accelerate certain refactoring operations, yet acceleration might encourage changes that aren’t architecturally justified. A developer manually refactoring code faces natural friction that prompts reconsidering whether the change matters; that friction disappears when agents make changes at button-click speed.
Furthermore, agentic refactoring connects to the broader evolution of developer-AI collaboration models. This research demonstrates that effective AI assistance requires clear problem scoping and human oversight, lessons applicable far beyond refactoring. As organizations adopt agentic tools more broadly, understanding these collaboration patterns becomes crucial for maximizing benefits while maintaining code quality.
The study also speaks to code review practices’ future. Traditional review processes emerged when code changes required significant human effort to create; reviewing before committing made sense as a quality gate. As agents generate candidate changes at high volume, review processes may require evolution, potentially incorporating automated screening that identifies which agent-generated changes merit human attention.
Finally, this research contributes to ongoing discussions about technical debt management. Rather than viewing technical debt as something requiring dedicated refactoring sprints, agentic tools enable continuous, incremental improvement. This shift from episodic to continuous technical debt management represents a potentially significant change in how organizations maintain code quality over time.
Conclusion: Pragmatic Optimism with Appropriate Caution
The empirical evidence presented in this research enables a nuanced, pragmatic perspective on agentic refactoring. These tools demonstrably contribute value to software maintenance, particularly for consistency-oriented improvements and medium-level refactorings that reduce class complexity. Agents excel at applying rules systematically across large codebases, catching opportunities human developers might miss through simple fatigue.
Yet the evidence equally clearly establishes limitations. Agents struggle with high-level design transformations requiring architectural vision. They optimize for measurable metrics without necessarily improving experiential code quality. Their effectiveness depends critically on precise task definition and human oversight. They function best as collaborative teammates rather than autonomous masters of code quality.
For organizations considering agentic refactoring adoption, the path forward involves integrating these tools into workflows that maintain human expertise and judgment at critical decision points. The most productive approach likely involves using agents to handle low-level consistency improvements and proposing medium-level refactorings, while reserving high-level architectural decisions for experienced developers. Testing and incrementally committing changes, rather than trusting bulk agent-generated transformations, remains essential practice.
As language models continue advancing and specialized agent architectures emerge, agentic refactoring capabilities will likely expand. This research provides a valuable empirical baseline for tracking that evolution, enabling future studies to measure genuine capability improvements rather than relying on subjective assessments. In an era of increasing AI integration into development workflows, such grounded empirical evidence proves invaluable for navigating the technology thoughtfully, capturing genuine benefits while avoiding pitfalls that enthusiastic adoption might introduce.